Basically I have 2 hour experience with Dgraph and I am doing research if Dgraph supports a few basic use-case. Upon some research I have come to an understand that since Dgraph is distributed some operations like select * are not performance friendly.
I will be doing research and updating my post with my understanding, and here are my use cases:
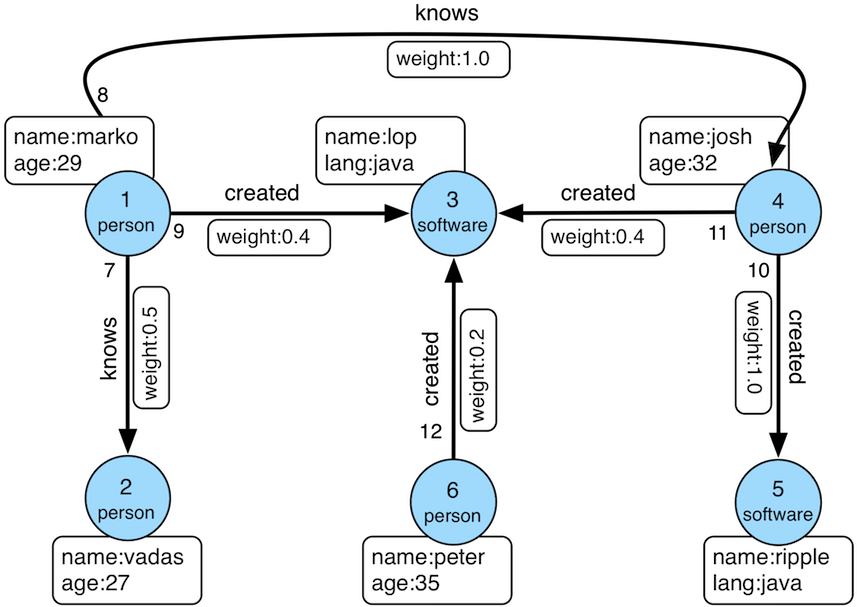
Sample Graph: http://tinkerpop.apache.org/docs/3.2.9/images/tinkerpop-modern.png
Find all types of nodes/vertices in the database.
Find all nodes/vertices that belong to type “people”
All the people who created a software
disclaimer: sample queries are for understanding purposes and might not be 100% accurate.
karan28aug
June 28, 2018, 6:03am
2
Data Loaded:
{
set {
_:michael <name> "Michael" .
_:michael <age> "39" .
_:michael <friend> _:amit .
_:michael <friend> _:sarah .
_:michael <friend> _:sang .
_:michael <friend> _:catalina .
_:michael <friend> _:artyom .
_:michael <owns_pet> _:rammy .
_:amit <name> "अमित"@hi .
_:amit <name> "অমিত"@bn .
_:amit <name> "Amit"@en .
_:amit <age> "35" .
_:amit <friend> _:michael .
_:amit <friend> _:sang .
_:amit <friend> _:artyom .
_:luke <name> "Luke"@en .
_:luke <name> "Łukasz"@pl .
_:luke <age> "77" .
_:artyom <name> "Артём"@ru .
_:artyom <name> "Artyom"@en .
_:artyom <age> "35" .
_:sarah <name> "Sarah" .
_:sarah <age> "55" .
_:sang <name> "상현"@ko .
_:sang <name> "Sang Hyun"@en .
_:sang <age> "24" .
_:sang <friend> _:amit .
_:sang <friend> _:catalina .
_:sang <friend> _:hyung .
_:sang <owns_pet> _:goldie .
_:hyung <name> "형신"@ko .
_:hyung <name> "Hyung Sin"@en .
_:hyung <friend> _:sang .
_:catalina <name> "Catalina" .
_:catalina <age> "19" .
_:catalina <friend> _:sang .
_:catalina <owns_pet> _:perro .
_:rammy <name> "Rammy the sheep" .
_:goldie <name> "Goldie" .
_:perro <name> "Perro" .
}
}
Find all types of nodes:
{
all_nodes(func: has(_predicate_)) {
expand(_all_) {
expand(_all_)
}
}
}
This will return all the data loaded.
Find all the data that is related to particular person(Michael):
{
expand(func: allofterms(name, "Michael")) {
expand(_all_) {
expand(_all_) {
expand(_all_)
}
}
}
}
I hope it is helpful for you.
rgupta
June 28, 2018, 6:13am
4
if there are two type of node “Teacher” and “Student” and both have same property and value ie “name”: “Amit”, then which data will return
karan28aug
June 28, 2018, 6:25am
5
You can use @filter accordingly.
https://docs.dgraph.io/query-language/#connecting-filters
ok thanks will try it out

{kind=link}