I think there is a massive amount of misunderstanding / people talking over each other in this thread. So please allow me to spend some time to clarify. I apologize in advance if I seem condescending. However, there are twofold benefits to this:
- I get to be clearer about my understanding of Dgraph things. Hopefully this does for you too.
- There’s always someone in the ten thousand.
Concepts
First, some concepts. This is useful because it frames the discussion. I will not use new terms without first introducing them first. I find this adds a lot of clarity to the situation.
Node
What is a node? A node in Dgraph is just a number - the UID.
But don’t nodes usually hold some data? We’ll get to that in a bit. For now, a node is just a number.
Edge
What is an edge? An edge is a connection between two nodes. In Dgraph, an edge is defined as
<uid> --- Predicate --- <uid>
Now, a Predicate is just the “type” of edge. Let’s continue with a more concrete example.
Let’s say there are two “types” of predicates: knows and reads.
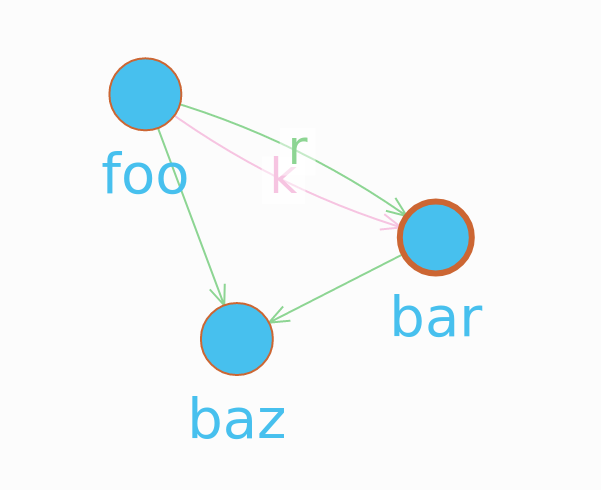
A node (UID) may have multiple edges to multiple other nodes (UIDs). A imagery representation is presented below (ignore the red lines in all the images in this post
This graph is represented by a list of edges, which we can put in a table below:
| From |
To |
Predicate |
| 0x1 |
0x2 |
knows |
| 0x1 |
0x2 |
reads |
| 0x1 |
0x3 |
reads |
| 0x2 |
0x3 |
reads |
One thing about this representation is that every edge is unique. You cannot repeat a row in the table above.
Where Is The Data Stored
So far we’ve talked about the abstract graph with some concrete examples. The graph in the example above is still just a bunch of numbers in a table. Not very useful (unless you’re a mathematician). No, we need to understand what each node represents.
So, let’s say each node represents a person. And all people have names.
So we want to add names to the nodes. How does this happen in Dgraph? Well, we use… edges!
We update the graph to be as follows:
There are some new things in here. Specifically there are edges that are dashed with the label “value”. These are not real edges in the graph. Rather, these are pointers to where the data is stored (i.e. in badger).
The table is now something like this:
| From |
To |
Predicate |
Data |
Data Type |
| 0x1 |
0x2 |
knows |
|
|
| 0x1 |
0x2 |
reads |
|
|
| 0x1 |
0x3 |
reads |
|
|
| 0x2 |
0x3 |
reads |
|
|
| 0x1 |
0x4 |
name |
“foo” |
string |
| 0x2 |
0x5 |
name |
“bar” |
string |
| 0x3 |
0x6 |
name |
"baz |
string |
Types
So now our graph is a LOT more complicated. We can use the type system to define things better.
I’ll introduce a little bit of DQL syntax here because the syntax is quite clear in reflecting the semantics.
type Person {
name
}
Here we are saying a Person is any node with a predicate name. The graph now looks like this
So what happens when we define two other types?
type Nerd {
reads
}
type Fixer {
knows
}
0x1 is now a Person, a Nerd and a Fixer! 0x2 is now a Person and a Nerd.
This is also commonly called “structural typing” in the programming language world. If you use Go, you may think of these “types” we have designed so far as interfaces.
Unfortunately Graphviz, the software I use to draw these graphs, are unable to handle these sorts of structural typing. You can imagine drawing overlapping boxes representing each connection..
Structural typing is really cool. But it’s probably not such a wise thing to do in a highly performant graph database either.
So instead, in Dgraph, types are nominal. They are represented by… edges!
Here, I coloured the types yellow and omitted the usual UID things. It’s also short one edge from 0x3 to nerd from summoning Beelzeebub from the fiery depths of Hell. You should be thankful I didn’t add that for this example.
Putting it all to practice
So, let’s put it all into practice. What are the implications of the paragraphs above?
Set up
To start off, let’s create a schema:
<knows>: [uid] .
<name>: string .
<reads>: [uid] .
<title>: string @index(hash) .
type <Fixer> {
knows
}
type <Nerd> {
reads
}
type <Person> {
name
}
And now, let’s put in some data:
{
set {
_:x1 <name> "foo" .
_:x1 <dgraph.type> "Person" .
_:x2 <name> "bar" .
_:x2 <dgraph.type> "Person" .
_:x3 <name> "baz" .
_:x3 <dgraph.type> "Person" .
_:x1 <reads> _:x2 .
_:x1 <knows> _:x2 .
_:x1 <reads> _:x3 .
_:x1 <dgraph.type> "Nerd" .
_:x1 <dgraph.type> "Fixer" .
_:x2 <reads> _:x3 .
_:x2 <dgaph.type> "Nerd" .
// in the picture below, x4 is 0x7
_:x4 <name> "quux" .
_:x4 <reads> _:x3 .
}
}
The graph you should have in your head should look something like this (apologies for the SPECTRE-ish layout. I’m not Blofeld. The circo layout engine would not draw clusters)
I added two things in this picture (when compared to the previous):
- I added 0x7 (“quux”) and 0x8, which I have labelled in a box called “untyped”
- I added the
string type, of which are the type of names.
Now we are ready to see the implications of all that was written so far. We will do this in a narrative style (i.e. I will show you results that don’t conform to your expectation, and then show you how to modify the query to work towards what you want)
First Attempt
We may query for anything that has a type (something @NonLogicalDev had nearly correct):
Let’s start with this:
{
q(func:has(<dgraph.type>)) @filter(not(type(<dgraph.graphql>))) @recurse {
expand(_all_)
}
}
This results in the following JSON:
"data": {
"q": [
{
"name": "bar"
},
{
"name": "baz"
},
{
"name": "foo"
}
]
},
All it returns are edges with the type "name"! Whatever happened to the other edges we defined?
Simply put, they were not expanded. This is because _all_ is a rather misleading term. It only expands all terminal edges (i.e. edges that lead to a value of a primitive type). It doesn’t expand predicates that are themselves graphs (i.e. subgraphs).
We can however, tell Dgraph to expand even the subgraphs. This is done by the @recurse directive.
Second Attempt: with @recurse
Adding @recurse, the query now looks like this:
{
q(func:has(<dgraph.type>)) @filter(not(type(<dgraph.graphql>))) @recurse {
uid
expand(_all_)
}
}
On my machine, this returns:
The JSON result is as follows:
"data": {
"q": [
{
"uid": "0x11",
"reads": [
{
"uid": "0x12",
"name": "baz"
}
],
"name": "bar"
},
{
"uid": "0x12",
"name": "baz"
},
{
"uid": "0x14",
"reads": [
{
"uid": "0x11",
"name": "bar"
},
{
"uid": "0x12",
"name": "baz"
}
],
"name": "foo",
"knows": [
{
"uid": "0x11",
"name": "bar"
}
]
}
]
}
Here you can see all the relevant non-meta edges have been returned correctly. You can simply parse the JSON for the predicates for your “inbound” or “outbound” edges
Job Done! Or Is It?
Querying for any nodes that has a <dgraph.type> and then adding @recurse seems to have done the job. But this doesn’t really fulfill what @labs20, @NonLogicalDev and @fosskers wants.
What they want is to input a UID, and then get all the predicates. Simple enough. Let’s try the following query:
{
q(func:uid("0x14")) @recurse {
uid
expand(_all_)
}
}
And the results are as follows:
"data": {
"q": [
{
"uid": "0x14",
"name": "foo",
"knows": [
{
"uid": "0x11",
"name": "bar"
}
],
"reads": [
{
"uid": "0x11",
"name": "bar"
},
{
"uid": "0x12",
"name": "baz"
}
]
}
]
}
Once again, you can just traverse the JSON to pick up all the keys as predicates that the node 0x14 (“foo”) has.
But Wait! I Don’t See Quux
You may have noticed that you do not see "quux" anywhere in any of the results. Why is that? That’s because _all_ only works on nodes with types.
So the following query
{
q(func:uid("0x13")) @recurse {
uid
expand(_all_)
}
}
Would not even return name, which is a terminal edge:
"data": {
"q": [
{
"uid": "0x13"
}
]
}
If you have untyped data, your best bet would be to list all the known predicates and query for it:
{
q(func:uid("0x13")) @recurse {
uid
knows
reads
name
}
}
which will yield
"data": {
"q": [
{
"uid": "0x13",
"reads": [
{
"uid": "0x12",
"name": "baz"
}
],
"name": "quux"
}
]
}
Moral of the Story
I can think of three lessons I learned from writing this post:
- Dgraph’s concept and representation of an edge is quite different to other graph databases’ concept and representation. Understanding the underlying representations is vital in understanding what you can do, and why what you want to do may not be the thing you want to use.
- Use
@recurse when you need to traverse the graph recursively.
- Types are friends, not food.
Footnotes