Graph + Vector vs Graph on Vector
Graph + Vector vs Graph on Vector
The next version of Dgraph will support both graph and vector data structures to allow multi-model queries on graph, vector, text, and geospatial information.
We’re seeking Private Beta participants & partners:
With each technology platform shift, data management software had to evolve to meet the needs of those new applications. The Web brought Big Data, Mobile brought on NoSQL, the web hit scale, SQL had to make room for Big Data. With this latest wave of LLMs, modern apps now need vectors and graphs.
The recent iterations of Language Models (LMs) are able to interpret large chunks of unstructured data (documents) and generate an encoding of that document expressed as a vector. In plain language, these LMs are able to explain the contents of a document as a list of numbers. That list of numbers, called a vector, can then be compared to other lists of numbers. This process is called vector search.
The ability to quickly compare chunks of unstructured data unlocks dozens of previously impossible use cases. Things like recommendations, fraud detection, entity resolution, and natural language processing all become significantly easier.
As powerful as this is, a known limitation of LLMs is that they are only as current as the data they are trained on. Thus, the LLM is usually behind the current state of the data. This can be overcome by adding contents that represent more current data in the question asked of the LLM.
We can iteratively store previously generated encodings in a database. Then, when asking the LLM to perform work, we can send over documents based on already stored encodings, improving the context from which the LLM can respond.
This workaround has led to the emergence of vector-first databases like Pinecone, Weaviate, and Milvus, while established data-stores like Postgres, Elasticsearch, Redis, and MongoDB have incorporated support for storing vector embeddings and similarity search.
Graph-based Indexes
In nearly all implementations of vector search for native vector databases and vector support in traditional databases, graphs and trees are used to index vectors. This graph structure enables efficient searches across very large sets of vectors.
Vectors are stored and then graphs are built as indexes on top of them in a Graphs-on-Vector (GOV) approach.
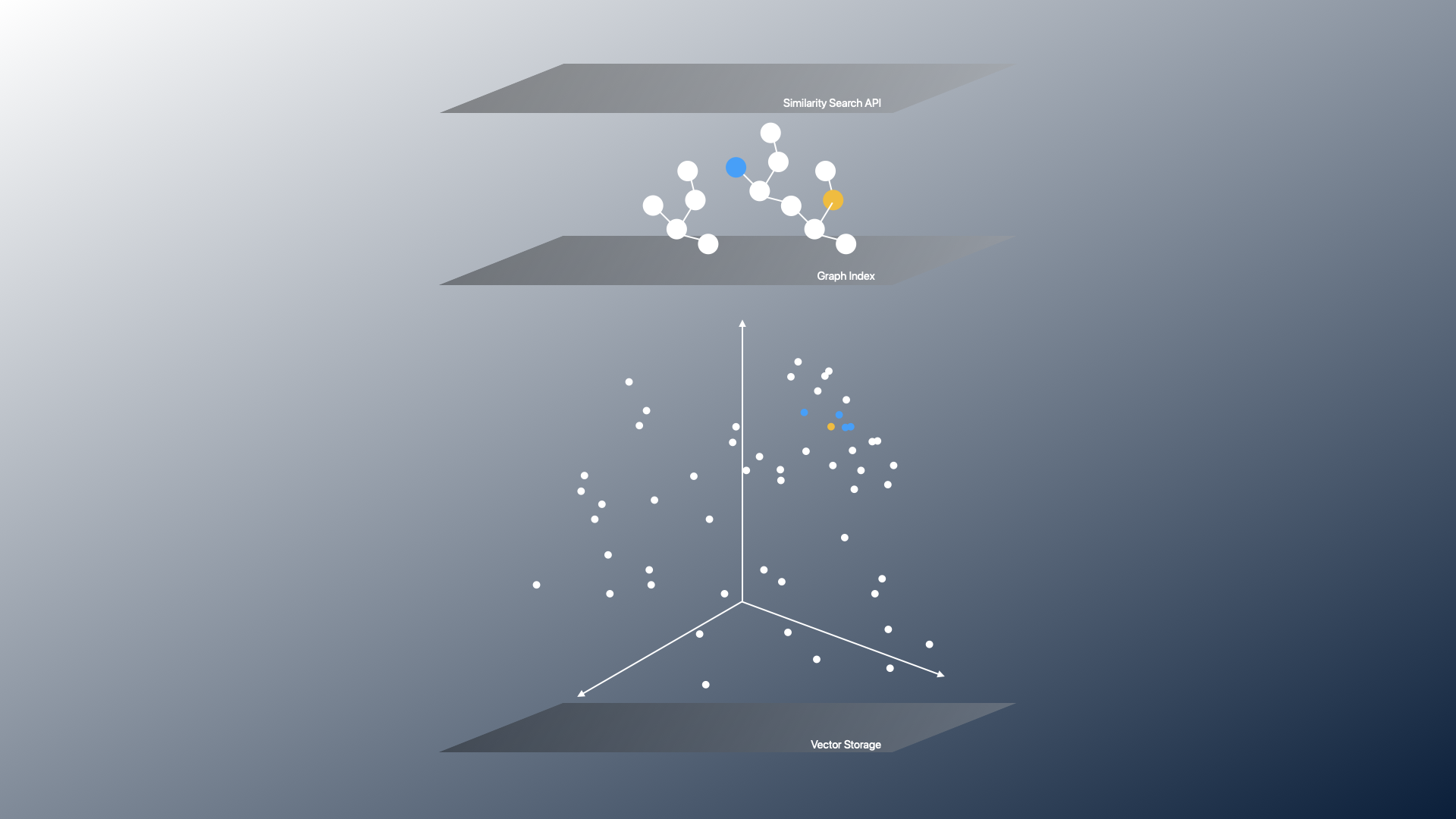
However, the GOV approach only partially harnesses the potential of graphs.
Graphs can be used to traverse multi-dimensional space to calculate adjacencies, but, more importantly, can represent structured data that explains the relationships between those entities.
Very few real-world AI applications can function without composite queries that retrieve data from a database’s structured and vector components. Recognizing this, we adopted a Graph-and-Vector (GAV) approach. In this approach, both graph and vector are primary components in Dgraph, allowing for multi-model queries on graph, vector, text, and geospatial information.
This unlocks things like model-output explainability and hallucination identification, and requires fewer systems to manage. i.e., not needing to ping 3 databases to check “what should we recommend, is it in stock, and is it within 2-day shipping of the buyer?”
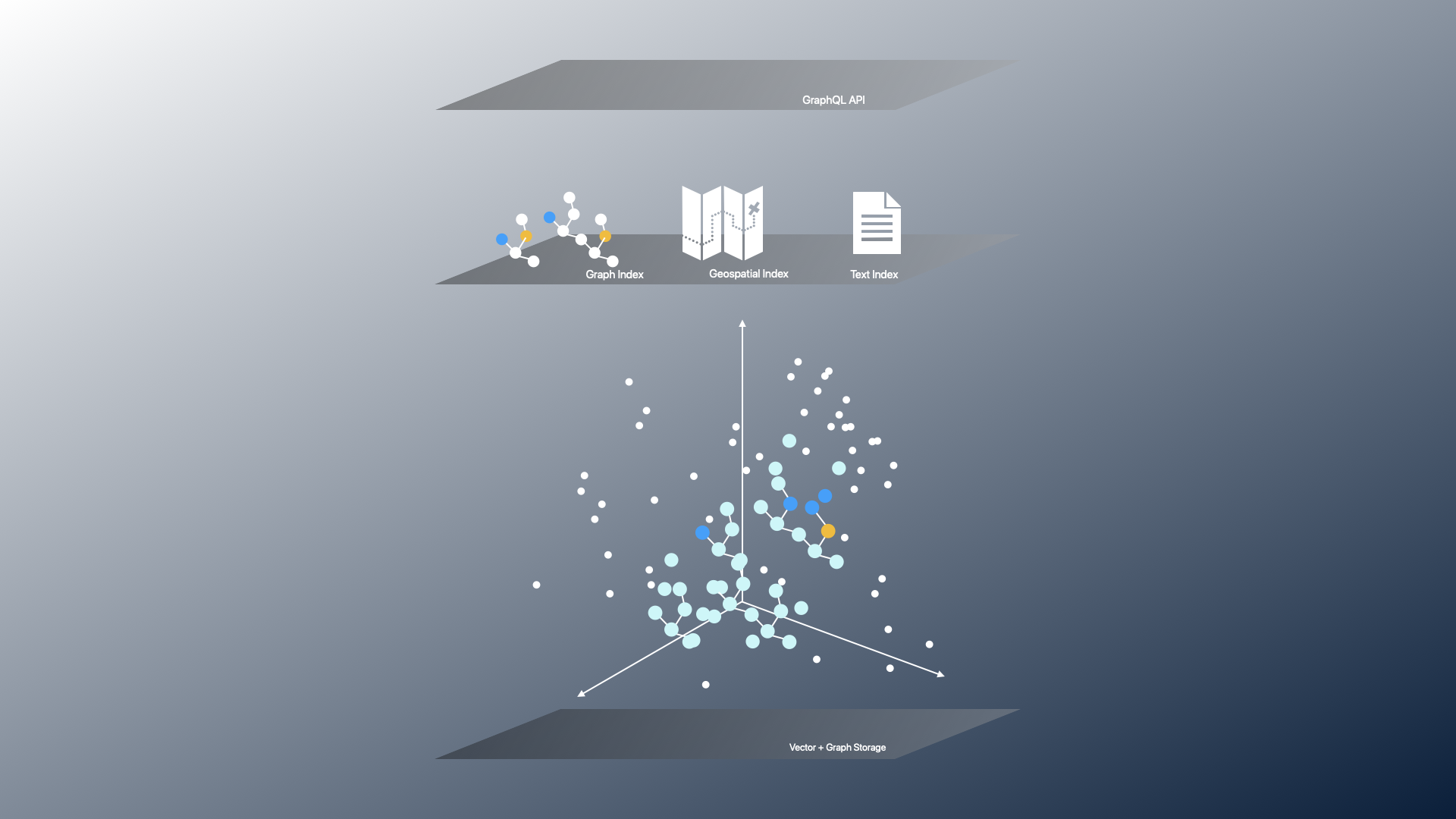
Dgraph’s ability to handle multi-model queries, ACID compliance, and scalability make it ideal as the transactional backend for AI applications.
We are excited about the new version of Dgraph being released soon. We are currently accepting Private Beta participants & partners to grant early access to the product preview, particularly for our active customers and community members.
Please provide your email and we’ll contact you:
This is a companion discussion topic for the original entry at https://dgraph.io/blog/post/20231010-graph-plus-vector-vs-graph-on-vector